Here, we are going to predict the outcome of climbing incidents (fatal or nonfatal) using text from climbing incident articles. This data set includes more possible predictors than the text alone, but for this model we will only use the text variable.
# A tibble: 6 × 5
ID `Accident Title` Publi…¹ Text Deadly
<chr> <chr> <dbl> <chr> <dbl>
1 1 Failure of Rappel Setup (Protection Pulled Out), I… 1990 "Col… NA
2 2 Failure of Rappel—Failure to Check System, British… 1990 "Bri… NA
3 3 Fall into Crevasse, Climbing Alone, Inadequate Equ… 1990 "Alb… NA
4 4 Fall into Crevasse, Climbing Unroped, British Colu… 1990 "Bri… NA
5 5 Fall Into Crevasse, Unroped, Inadequate Equipment,… 1990 "On … 1
6 6 Fall into Moat, Descending Unroped, Poor Position,… 1990 "Alb… 1
# … with abbreviated variable name ¹`Publication Year`
We’ll split our data into training and test portions
set.seed(1234)# Adding a fatality binary indicatorincidents2class <- incidents_df |>mutate(fatal =factor(if_else(is.na(Deadly) ,"non-fatal", "fatal")))# Splitting our data, stratifying on the outcomeincidents_split <-initial_split(incidents2class, strata = fatal)# Now for making our training and testing sets:incidents_train <-training(incidents_split)incidents_test <-testing(incidents_split)
We use recipe() from tidymodels to specify the predictor and outcome variables and the data.
# Making the recipe. We're saying we want to predict fatal by using Textincidents_rec <-recipe(fatal ~ Text, data = incidents_train)
Next we add some familiar pre-processing steps on our Text variable. We first tokenize the articles to word level, filter to the most common words, and calculate tf-idf.
# Adding steps to our reciperecipe <- incidents_rec %>%step_tokenize(Text) %>%step_tokenfilter(Text, max_tokens =1000) %>%step_tfidf(Text) #new one from textrecipes
Modeling
We use tidymodels workflow to combine the modeling components. There are several advantages of doing this: We don’t have to keep track of separate objects in our workspace. The recipe prepping and model fitting can be executed using a single call to fit() . If we have custom tuning parameter settings, these can be defined using a simpler interface when combined with tune.
Naive Bayes
# Making the workflow objectincidents_wf <-workflow() %>%add_recipe(recipe)
We want to use Naive Bayes to classify the outcomes.
nb_spec <-naive_Bayes() %>%set_mode("classification") %>%#set modeling contextset_engine("naivebayes") #method for fitting modelnb_spec
Naive Bayes Model Specification (classification)
Computational engine: naivebayes
Now we are ready to add our model to the workflow and fit it to the training data
# Fitting the model to our workflownb_fit <- incidents_wf %>%add_model(nb_spec) %>%fit(data = incidents_train)
Next up is model evaluation. We’ll stretch our training data further and use resampling to evaluate our Naive Bayes model. Here we create 10-fold cross-validation sets, and use them to estimate performance.
# Set the seed for reproducibilityset.seed(234)incidents_folds <-vfold_cv(incidents_train) #default is v = 10incidents_folds
To estimate its performance, we fit the model many times, once to each of these resampled folds, and then evaluate on the holdout part of each resampled fold.
We’ll use two performance metrics: accuracy and ROC AUC. Accuracy is the proportion of the data that is predicted correctly. The ROC curve plots the true positive rate against the false positive rate; AUC closer to 1 indicates a better-performing model, while AUC closer to 0.5 indicates a model that does no better than random guessing.
Now we’re going to try a more powerful algorithm: the random forest classifier.
# Specifying the modelrf_spec <-rand_forest() |>set_mode("classification") |>set_engine("ranger")
We’re first going to conduct an initial out-of-the-box model fit on the training data and prediction on the test test data. Assess the performance of this initial model.
# Initializing a workflow, fitting it to resamplesrf_workflow <-workflow() |>add_recipe(recipe) |>add_model(rf_spec)rf_fit <- rf_workflow |>fit(data = incidents_train)rf_rs <-fit_resamples( rf_workflow, incidents_folds,control =control_resamples(save_pred =TRUE))
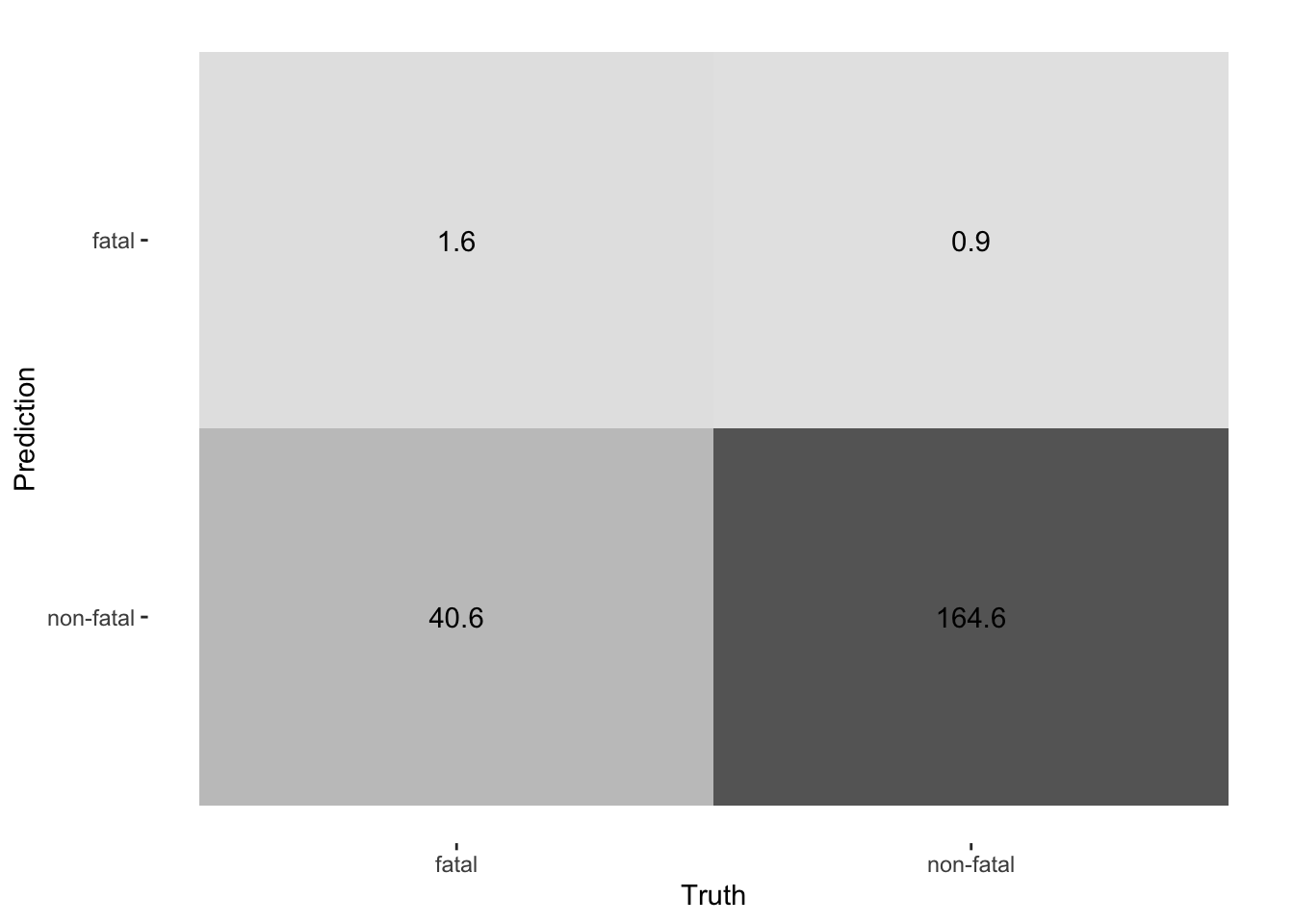
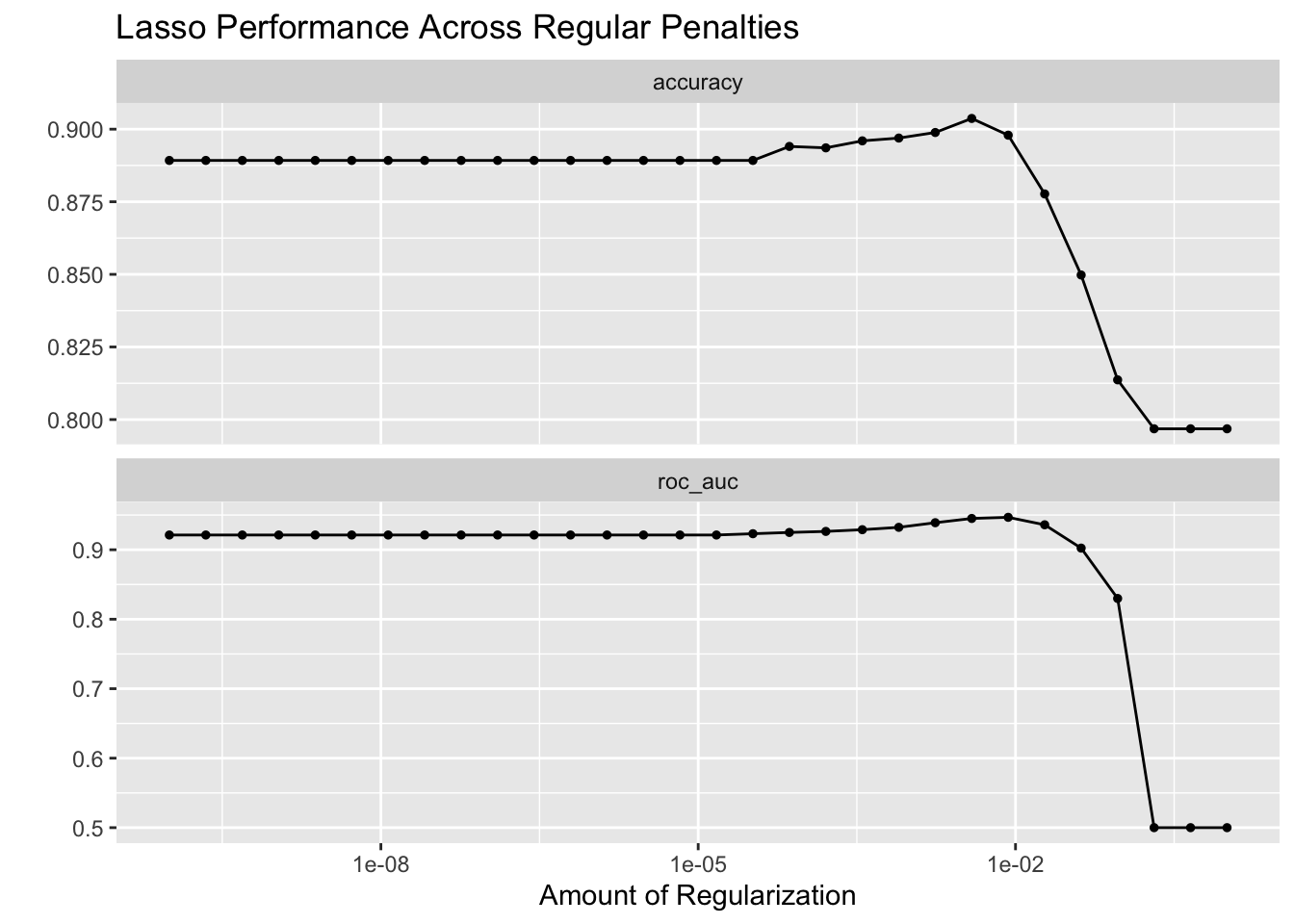
Initial model has an accuracy of 86% and roc_auc of 0.95. Not bad at all.
Now, we’re going to tune the hyperparameters:
# specifying which parameters to tune, adding this new model back into a workflowtune_rf_spec <-rand_forest(trees =tune(), mtry =tune(), min_n =tune()) |>set_mode("classification") |>set_engine("ranger")tune_rf_wf <-workflow() |>add_recipe(recipe) |>add_model(tune_rf_spec)set.seed(123)randf_grid <-grid_regular(trees(), min_n(), mtry(range(1:13)))doParallel::registerDoParallel() # running this in paralleltune_rs <-tune_grid(tune_rf_wf, incidents_folds, grid = randf_grid, control =control_resamples(save_pred = T, parallel_over ='everything'))
We then conduct a model fit using your newly tuned model specification and investigate the terms most highly associated with non-fatal, and fatal reports
# extracting our best hyperparameters:params <- tune_rs |>show_best("accuracy") |>slice(1) |>select(trees, mtry, min_n)best_trees_rf <- params$treesbest_mtry_rf <- params$mtrybest_min_n_rf <- params$min_n# Final model using our best parametersrandf_final <-rand_forest(trees = best_trees_rf,mtry = best_mtry_rf,min_n = best_min_n_rf) |>set_mode("classification") |>set_engine("ranger")# fit on the trainingrandf_final_fit <- tune_rf_wf |>update_model(randf_final) |>fit(data = incidents_train)
Unfortunately tidy doesnt support ranger and we are unable to see variable importance/terms most highly associated with different reports
Now, we’ll predict fatality of the reports in the test set. We can compare this prediction performance to that of the Naive Bayes and Lasso models.
# predict on the test, calculate RMSErf_testing_preds <-predict(randf_final_fit, incidents_test) |>bind_cols(incidents_test) |>mutate(truth =as.factor(fatal), estimate =as.factor(.pred_class)) |>metrics(truth = truth, estimate = estimate)rf_testing_preds
# A tibble: 2 × 3
.metric .estimator .estimate
<chr> <chr> <dbl>
1 accuracy binary 0.812
2 kap binary 0.119
Unfortunately, our predictions got worse as we tuned the model. This could be due to bad combinations chosen by the grid space, which is likely since our tuning grid isn’t very big. Our random forest model also performs worse than the lasso model (which scored 92% accuracy), but slightly better than the Naive Bayes model (81% accuracy)
Embeddings
First, let’s calculate the unigram probabilities – how often we see each word in this corpus.
# A tibble: 25,205 × 3
word n p
<chr> <int> <dbl>
1 rope 5129 0.00922
2 feet 5101 0.00917
3 climbing 4755 0.00855
4 route 4357 0.00783
5 climbers 3611 0.00649
6 climb 3209 0.00577
7 fall 3168 0.00569
8 climber 2964 0.00533
9 rescue 2928 0.00526
10 source 2867 0.00515
# … with 25,195 more rows
So now we have the probability of each word.
Next, we need to know how often we find each word near each other word – the skipgram probabilities. In this case we’ll define the word context as a five-word window. We’ll slide that window across all of our text and record which words occur together within that window. Let’s write some code that adds an ngramID column that contains constituent information about each 5-gram we constructed by sliding our window.
skipgrams <- incidents_df |>unnest_tokens(ngram, Text, token ="ngrams", n =5) |>mutate(ngramID =row_number()) |> tidyr::unite(skipgramID, ID, ngramID) |>unnest_tokens(word, ngram) |>anti_join(stop_words, by ='word')
Now we use widyr::pairwise_count() to sum the total # of occurrences of each pair of words.
The next step is to normalize these probabilities, that is, to calculate how often words occur together within a window, relative to their total occurrences in the data.
normalized_prob <- skipgram_probs |>filter(n>20) |>rename(word1 = item1, word2=item2) |>left_join(unigram_probs |>select(word1 = word, p1 = p), by ='word1') |>left_join(unigram_probs |>select(word2 = word, p2 = p), by ='word2') |>mutate(p_together = p/p1/p2)normalized_prob
Now we have all the pieces to calculate the point-wise mutual information (PMI) measure. It’s the logarithm of the normalized probability of finding two words together. PMI tells us which words occur together more often than expected based on how often they occurred on their own.
Then we convert to a matrix so we can use matrix factorization and reduce the dimensionality of the data.
We do the singluar value decomposition with irlba::irlba(). It’s a “partial decomposition” as we are specifying a limited number of dimensions, in this case 100.
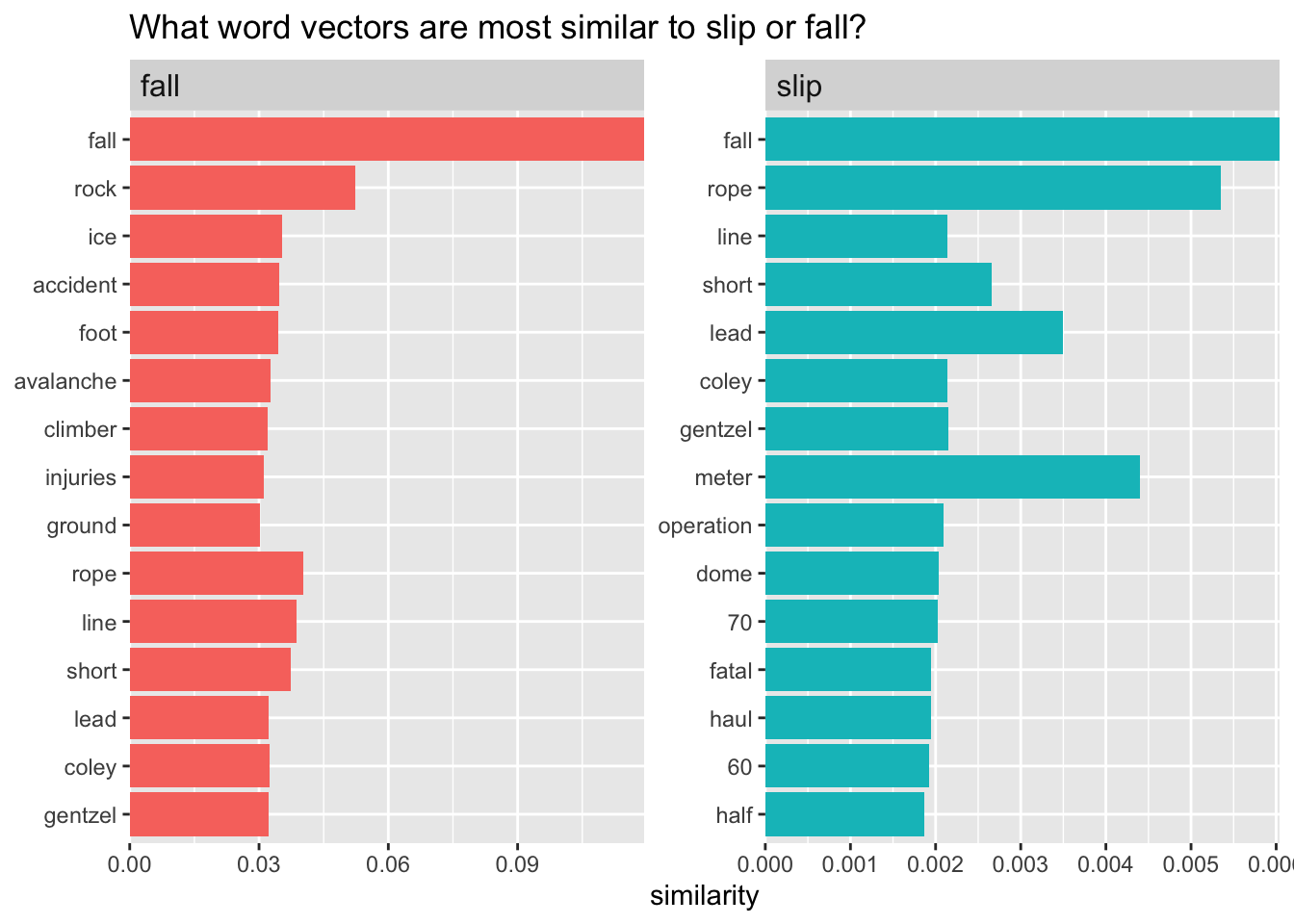
These vectors in the “u” matrix are contain “left singular values”. They are orthogonal vectors that create a 100-dimensional semantic space where we can locate each word. The distance between words in this space gives an estimate of their semantic similarity.
Here’s a function written by Julia Silge for matching the most similar vectors to a given vector.
Now we’ll use the data from our Nexis Uni query from Week 2, to create a set of word embeddings. We’ll take essentially the same steps we did previously
We can use the glove6b data to create a set of 100-dimensional GloVe word embeddings. These embeddings were trained by researchers at Stanford on 6 billion tokens from Wikipedia entries.
New names:
Rows: 400000 Columns: 102
── Column specification
──────────────────────────────────────────────────────── Delimiter: "," chr
(1): token dbl (101): ...1, d1, d2, d3, d4, d5, d6, d7, d8, d9, d10, d11, d12,
d13, d14...
ℹ Use `spec()` to retrieve the full column specification for this data. ℹ
Specify the column types or set `show_col_types = FALSE` to quiet this message.
• `` -> `...1`
# Convert the data frame to a matrixglove6b_matrix <-as.matrix(glove6b[,-(1:2)]) # Set the row names of the matrix to be the token column from the data framerownames(glove6b_matrix) <- glove6b$token
Now, lets test them out with the cannonical word math equation on the GloVe embeddings: “berlin” - “germany” + “france” = ?
# A tibble: 400,000 × 2
token similarity
<chr> <dbl>
1 paris 34.4
2 france 31.5
3 french 28.0
4 de 28.0
5 le 26.6
6 london 25.4
7 la 24.3
8 brussels 23.3
9 berlin 23.3
10 lyon 22.2
# … with 399,990 more rows
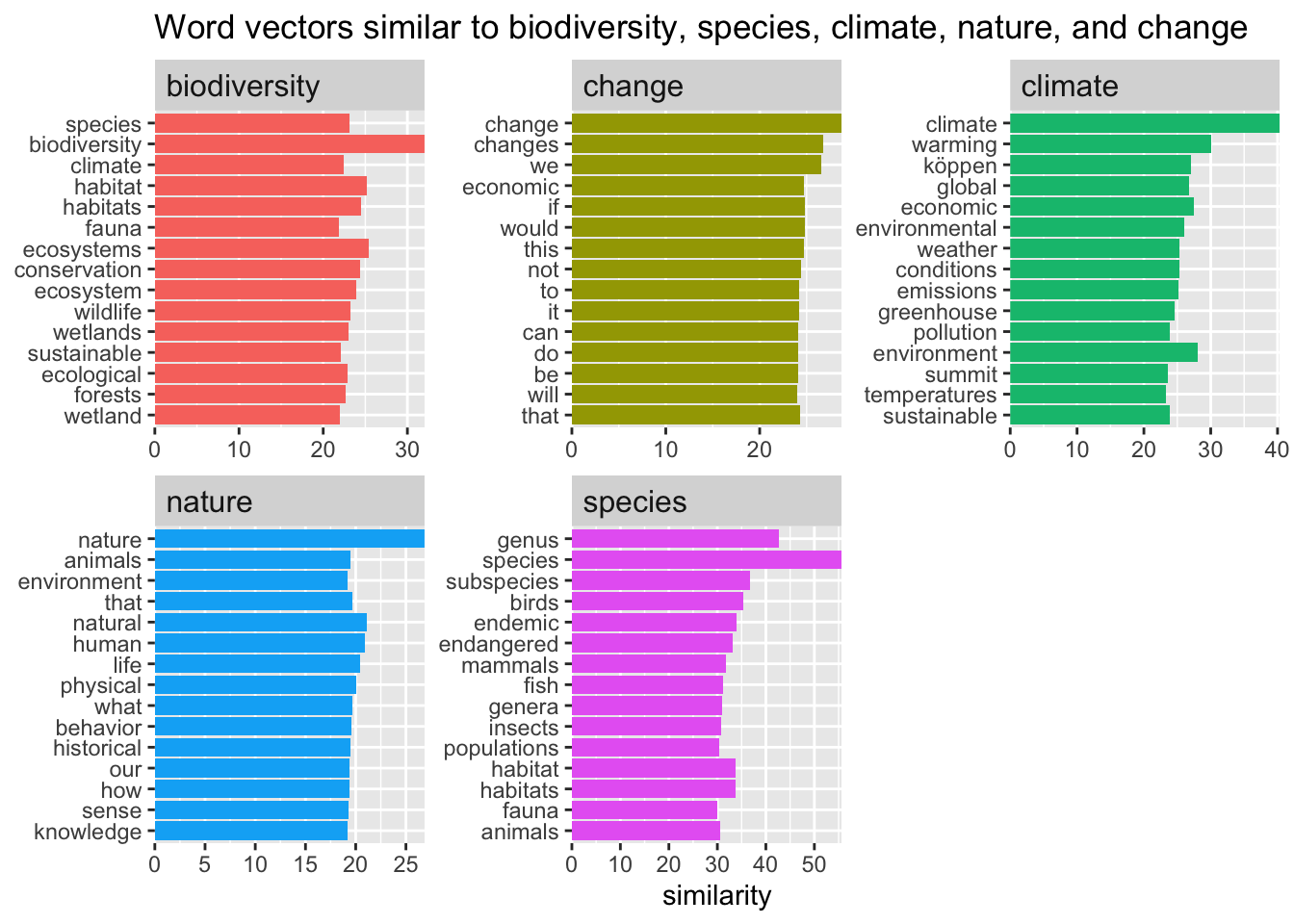
We can recreate our earlier analyses using the GloVe embeddings in places of the embeddings we trained.
The synonym similarities for the GloVe embeddings are much higher than for the articles I selected. The synonyms chosen are also much more pertinent to each word. This is expected since the GloVe embeddings are much more comprehensive.
# A tibble: 400,000 × 2
token similarity
<chr> <dbl>
1 change 28.7
2 changes 26.7
3 we 26.5
4 if 24.9
5 would 24.8
6 this 24.7
7 economic 24.7
8 not 24.4
9 that 24.3
10 to 24.2
# … with 399,990 more rows